
El objetivo principal del estudio es optimizar el proceso de detección de fraudes eléctricos existentes en una empresa de distribución de energía eléctrica a través de análisis estadísticos a fin de disminuir las pérdidas de energía eléctrica.
Para el desarrollo del estudio es necesario utilizar metodologías y herramientas especializadas, destacándose la construcción de modelos de pronóstico y clasificación mediante técnicas estadísticas Unidimensionales y Multivariantes. Estas técnicas permiten extraer de la base de datos comercial, tendencias y factores definitorios de irregularidades comerciales mediante la consideración de variables determinantes de patrones de consumo entre otros.
Para llevar a cabo este análisis se utilizará el software estadístico R, el cual es de obtención gratuita, y fue elegido por su versatilidad en la visualización de gráficos, elaboración de análisis estadísticos entre otros aspectos, el cual ayudará a conseguir un mayor entendimiento de la matriz de datos y las relaciones existentes entre las variables analizadas.
Introducción
La energía eléctrica contribuye a la mejora de la calidad de vida y al desarrollo sostenible de los países. Sin embargo, los factores naturales, fraude de energía eléctrica, entre otros, han influido en el déficit energético que atraviesa nuestro país al igual que otros a nivel mundial.
La Organización de Naciones Unidas (ONU) señala que 1/3 de la población mundial no tiene acceso al servicio de electricidad.
El fraude de energía eléctrica impacta directamente en el incremento de las pérdidas no técnicas y se debe principalmente a consumos no registrados producidos por la manipulación a los equipos de medición de energía eléctrica y/o conexiones a la red no autorizadas, por las empresas de servicio eléctrico. Actualmente, dichas empresas aplican distintas acciones de reducción de pérdidas no técnicas para garantizar la sustentabilidad financiera y contribuir a la disminución del déficit energético.

La detención de fraudes en las redes de distribución eléctrica es uno de los principales retos para las empresas eléctricas en Venezuela. En el año 1997 C.A Electricidad de Valencia (ELEVAL) ubicada en la Ciudad de Valencia, Estado Carabobo, poseía un nivel de pérdida global de 38,15%. En tal sentido, se inició un proyecto para la disminución de pérdidas no técnicas donde se aplicaron diferentes estrategias y procedimientos eficaces, obteniendo una efectividad cercana al 35% en las inspecciones ejecutadas; es decir, de cada 100 inspecciones se detectaban 35 suministros con fraude.
Al cierre del año 2009, ELEVAL, en proceso de fusión con la Corporación Eléctrica Nacional, tuvo un valor de pérdida global de 14,14% (pérdidas técnicas cerca de 8,40% y pérdidas no técnicas 5,74%) y una efectividad cercana al 13%, lo que representó una disminución de 22 puntos en la efectividad detección de fraudes y aumento de los costos en casi 2,7 veces en relación al año 1997.

Para que el proyecto de reducción de pérdidas no técnicas sea rentable es necesario mejorar la efectividad en la detección de fraude y los procesos de análisis e inspección de los suministros. En tal sentido, la Unidad de Protección de Ventas inició un estudio asociado a la detección de patrones de comportamiento de los suministros con fraude, basándose en herramientas estadísticas de clasificación, entre ellas el Análisis Unidimensional, Multivariado y de Conglomerados, que manejan mayor volumen de datos y obtienen resultados con mejor precisión en menor tiempo. En el siguiente trabajo se muestra el desarrollo, implementación y resultados de las herramientas utilizadas.
1- El Problema: Detección de fraudes eléctricos
En el año 1997 ELEVAL poseía un nivel de pérdida global de 38,15% lo que originó una alerta e incentivó la implementación de un proyecto para la disminución de las pérdidas totales, aplicando diferentes estrategias en los grupos de clientes de mayor consumo (Clientes Industriales y Comerciales) durante el período 1997-2002 se logró reducir a 22,31% (cerca de 16 puntos porcentuales, ver figura N° 1). Entre las estrategias estaba el análisis del balance energético por circuito y las inspecciones masivas por rutas de lecturas, sin discriminar las desviaciones y/o variaciones de consumo de los suministros.
En el año 2003 la empresa creó la Unidad de Protección de Ventas, con el fin de planificar, programar, analizar, controlar el proceso de detección y normalización de los suministros con presuntos fraudes; la misma cuenta con un personal especializado, procedimientos, metodologías y un sistema de gestión comercial (OPEN SGC). Esto contribuyó a la reducción de los costos operativos asociados al proyecto de reducción de pérdidas no técnicas.

Para el año 2004 se inició la implementación del proyecto de control de pérdidas no técnicas con la instalación de medidores denominados Totalizadores, en las salidas de los bancos de transformación, principalmente con carga tipo residencial. Estos medidores permiten realizar el balance energético entre la energía despachada y la energía facturada total de los suministros asociados al transformador, los mismos contribuyeron a reducir a 15,08% las pérdidas globales al cierre del año 2006 (cerca de 9 puntos porcentuales en relación al año 2004). Ver figura N° 1.
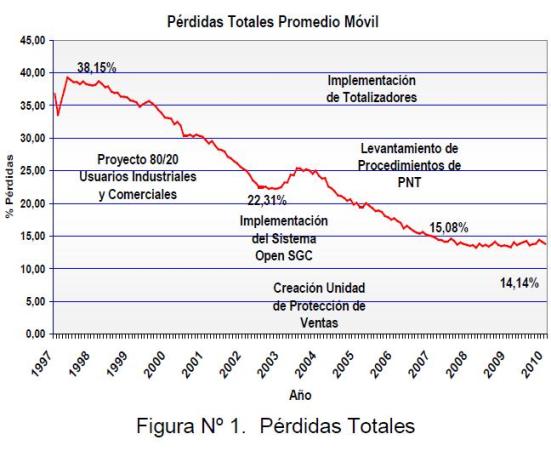
Figura 1: Pérdidas Totales.
Las estrategias de reducción de pérdidas se mantuvieron en los años siguientes, cerrando en 14,14% las pérdidas globales para el año 2009 (ver figura N° 1). Ese año los costos asociados a la detección de un fraude presentaron un incremento de 136% (en relación al inicio del proyecto), debido principalmente a la baja efectividad en la detección de fraudes (13%), ver figura N° 2. Situación que lleva a investigar nuevas tecnologías y metodologías para mejorar dicha efectividad.
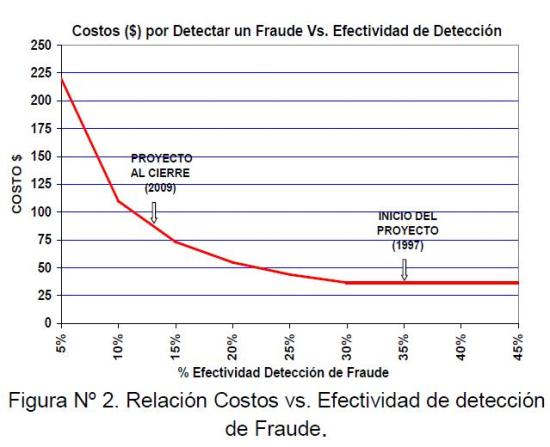
Figura 2: Relación Costos vs. Efectividad de detección de Fraude.
Se considera que la disminución en la efectividad de detección de fraudes se debe a:
• Bajo nivel de pérdidas de energía y menor cantidad de suministros con fraude.
• Evolución tecnológica de los usuarios al cometer algún tipo de fraude.
• Vulnerabilidad y errores en la base de datos de algunos clientes en el Sistema de Gestión OPEN SGC.
• Disminución de la calidad en el análisis de detección de fraude debido a sobrecarga de actividades asignadas por analista, debilidad en la aplicación de la metodología de análisis y desmotivación.
En la figura Nº 3 se muestra la Efectividad de Detección de Fraude vs. Pérdidas Totales.
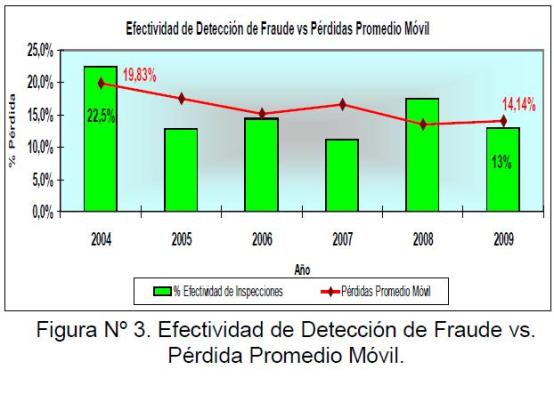
Figura 3: Efectividad de Detección de Fraude vs. Pérdida Promedio Móvil.
Ante este abanico de posibilidades se persigue optimizar y mejorar el proceso de detección de fraudes de suministros a través de estudios estadísticos, como las técnicas de clasificación (Análisis Unidimensional, Multivariado y de Conglomerados), que identifican patrones de comportamientos de suministros.
2- Metodología de análisis de base de datos para la detección de fraude
La base de datos de los clientes de ELEVAL está conformada aproximadamente por 135.000 suministros, los mismos son analizados por diferentes áreas de la Unidad de Protección de Ventas. A continuación se muestra la distribución de las bases de datos:
• Suministros anómalos: Cerca de 45.000 suministros (33% del total) que en un periodo de 12 meses presentan tres (3) desviaciones de facturación entre un -50% y -80% respecto a su consumo promedio.
• Suministros con probable reincidencia: Cerca de 30.000 suministros (22% del total) que fueron normalizados por presentar algún tipo de fraude.
• Suministros asociados a medidores totalizadores: Cerca de 125.550 suministros (93% del total).
• Suministros clientes industriales y comerciales. Cerca de 21.000 suministros (16% del total).
Los suministros pueden ser monitoreados simultáneamente por las distintas áreas.
El análisis de la base de datos de un suministro contempla:
• Conocimiento del cliente: Datos que representan información histórica del cliente, tarifa, actividad económica, consumo histórico, ubicación geográfica, entre otros.
• Datos de interés: Corresponde a las reclamaciones realizadas por el cliente, inspecciones ejecutadas anteriormente, fraudes o anomalías detectadas, entre otros.
• Solvencia de pago: Corresponde a la facturación, efectividad de la cobranza, cortes de energía ejecutados.
A continuación se muestra en la figura Nº 4 la metodología de análisis de detección de fraude:
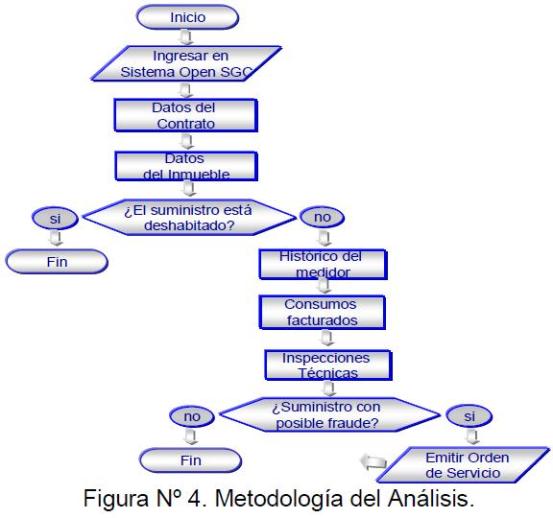
Figura 4: Metodología del Análisis.
3- Herramientas estadísticas
El estudio estadístico aplicado a la base de datos conlleva a la construcción de modelos matemáticos, por lo que es necesario determinar el conjunto de entrenamiento, validación y prueba con variables significativas que logren alcanzar un resultado confiable, no perceptibles a simple vista con el uso de las metodologías actuales de detección de fraude.
El análisis estadístico permite crear un sistema inteligente capaz de aprender de consumos históricos, ubicación geográfica, tarifa, actividad económica, entre otras variables; para extraer patrones, describir tendencias, predecir comportamientos, que al ser implementado en un computador facilita manejar grandes cantidades de datos, relacionar variables de distinta naturaleza, comprender y modelar la base de datos de suministros de una manera eficiente para la toma de decisiones, optimizando el proceso de detección de fraude.

La clasificación y jerarquización de las variables se deben tener en cuenta al momento del estudio estadístico.
Se estableció como metodología, la caracterización, tipificación e identificación de patrones, la cual se estructura en las siguientes etapas:
a) Descripción de la población a estudiar.
b) Procesamiento de la información (elaboración de la base de datos, clasificación y descripción de variables).
c) Análisis exploratorio de los datos.
d) Revisión y selección de variables.
e) Aplicación de técnicas estadísticas Multivariantes.
f) Determinación de Conglomerados (caracterización de los tipos de agrupamientos).
g) Validación.
h) Interpretación de resultados.
3.1- Análisis univariados y multivariantes
El análisis descriptivo unidimensional o univariado es el análisis primario que se realiza para medir una a una cada variable. Este análisis permitió evaluar la naturaleza de las variables, cuantificar algunos aspectos gráficos de los datos para evidenciar tendencias y preferencias de los clientes.
El análisis descriptivo multivariado se utiliza para describir el comportamiento de un conjunto de datos con más de una variable y sus objetivos son:
• Resumir de los datos mediante un pequeño conjunto de nuevas variables, construidas a través de transformaciones de las originales, con la mínima pérdida de información.
• Determinar de grupos en los datos.
• Clasificar nuevas observaciones en grupos definidos.
• Relacionar dos (2) o más conjuntos de variables.
En los métodos multivariados, se presume que las variables están correlacionadas, pero las observaciones sobre los individuos son independientes. Generalmente, también se supone que el conjunto de variables que intervienen en el análisis poseen una distribución normal multivariada. Esta suposición permite que el Análisis Multivariado se desarrolle paralelamente al correspondiente Análisis Univariado basado en una distribución normal.

Al aplicar técnicas estadísticas, se encuentran las dirigidas o motivadas por los individuos, las cuales se enfocan en las relaciones entre los mismos. Ejemplos: Análisis discriminante, Análisis de conglomerados y Análisis multivariado de varianza.
3.2- Análisis de componentes principales
Esta técnica de reducción de dimensionalidad tiene como objetivo transformar el conjunto de variables originales (correladas) en otro conjunto de variables incorreladas, denominadas componentes principales. Cada componente principal se obtiene como una combinación lineal de las variables originales y su importancia relativa se expresa en función del porcentaje de la varianza total.
Esta técnica tendrá éxito si un número pequeño de componentes explican un gran porcentaje de la varianza total. La aplicación de este estudio se enfoca en una técnica de análisis exploratorio que permite descubrir interrelaciones entre los datos y de acuerdo con los resultados, proponer los análisis estadísticos más apropiados, además de reducir la dimensionalidad de la matriz de datos para evitar las redundancias y destacar relaciones. En la mayoría de los casos, tomando sólo los primeros componentes, se puede explicar la mayor parte de la variación total contenida en los datos originales, así como, construir variables no observables (componentes) a partir de variables observables.
3.3- Análisis de conglomerados
Se optimiza la detección de fraudes en un conjunto de suministros mediante una herramienta estadística que permite particionarlos, con el fin de establecer, identificar y priorizar grupos homogéneos, en función de las similitudes que presenten entre la variación de consumo, ubicación geográfica, cantidad de anomalías, entre otros, los cuales pueden ser evidencias de casos con fraude.
Cuando se tiene un conjunto de observaciones multivariantes, donde requiere estudiar un conjunto de relaciones interdependientes y no se hace distinción entre variables dependientes e independientes, se puede realizar un Análisis de Conglomerados. Su objetivo principal es reducir el número de objetos y reunirlos en un número menor de grupos que la totalidad de los objetos y que éstos sean similares internamente y diferentes entre grupos. El Análisis de Conglomerados es la opción estratégica basada en la obtención e identificación de grupos, a objeto de describir la estructura latente de los datos y determinar patrones no observables directamente, como se ilustra en la figura Nº 5.
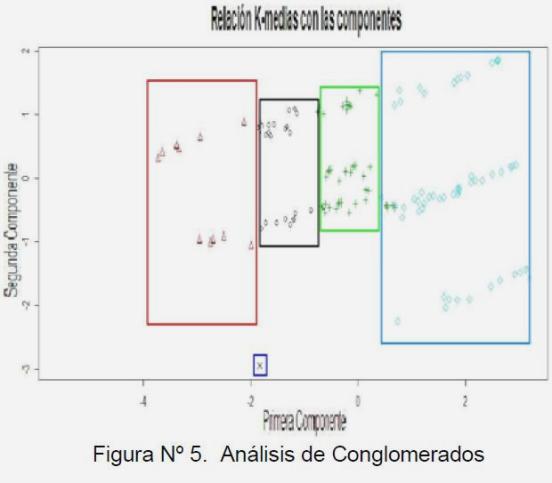
Figura 5: Análisis de Conglomerados.
Se desea repartir n datos, de dimensión p, en conglomerados o grupos (clusters) formados por datos que son “parecidos entre sí”. Los grupos no están definidos a priori. Básicamente, el objetivo del análisis es conseguir que los propios datos sugieran una agrupación adecuada.
Las técnicas de análisis de conglomerados se pueden usar, con algunas diferencias, tanto para datos xi = (xi1,xi2,…,xip) cuantitativos como cualitativos. En estos últimos las variables x1,x2,…,xp corresponden a códigos (usualmente numéricos) que identifican características cualitativas, como por ejemplo, Suministros con fraude (Con fraude =1, Sin fraude =0), presencia o ausencia de una característica.
Para el análisis de conglomerados se deben seguir las siguientes etapas:
a) La formulación del problema es lo más importante, es la selección de las variables en las que se basará la agrupación. El conjunto de variables seleccionado debe describir la similitud entre los objetos en términos relevantes para el problema de investigación.
b) La selección del método de clasificación de las variables empieza con el proceso de agrupación, estos métodos pueden ser jerárquicos o no jerárquicos. En este estudio se usarán aquellos que conducen a la obtención de particiones considerando un centro y agrupando los objetos de cada uno de ellos, en función de las distancias de los mismos, habiendo definido a priori el número de clases finales a considerar, a estos se les denomina no jerárquicos. En este estudio se implementó el método de agrupación no jerárquico, denominado K-medias y su algoritmo es el siguiente:
• Repartir las n observaciones en K grupos. Esta primera asignación se hace aleatoriamente. En cada uno de los grupos se obtiene el vector de medias (centro del grupo).
• Asignar secuencialmente cada observación al grupo cuyo centro este más cercano (usualmente, se utiliza la distancia euclídea de las observaciones a los centros de los grupos). En cada etapa se re-calcula el centro del grupo al que se añade una observación y el centro del grupo del que se elimina esa observación.
• Repetir el paso anterior hasta que no haya re-asignaciones.
c) Medición de la similitud: La similitud mide de acuerdo a la distancia entre los individuos, medidas de correlación o medidas de asociación. Al utilizar la distancia como medida de proximidad, las distancias más pequeñas indican mayor similitud.
d) Interpretación y perfiles de los grupos: El objetivo de esta etapa es el estudio de la variación de los clusters para asignar etiquetas que describan de un modo veraz su naturaleza. Con los perfiles y la interpretación de los conglomerados no sólo se consigue la descripción de los mismos, sino que proporcionan un medio para evaluar la correspondencia de los conglomerados obtenidos con aquellos supuestos por la experiencia práctica.
Mediante el uso de histogramas (ver figura Nº 6), se mostró gráficamente el comportamiento de las variables del estudio, lo cual suministró información necesaria para la interpretación de los grupos encontrados y conllevó a la realización de la respectiva etiqueta de identificación.
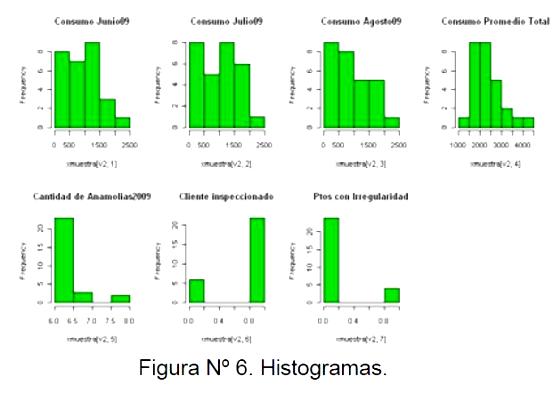
Figura 6: Histogramas.
4- Implementación y resultados de las herramientas estadísticas utilizadas
Para implementar las herramientas estadísticas Univariadas y Multivariantes, así como el análisis de conglomerados se seleccionó una base de datos de suministros anómalos de 43.053 clientes.
El análisis Univariado y Multivariante determinaron las variables dependientes del estudio, entre ellas: Consumos, cantidad de anomalías, tarifa y punto inspeccionado.

El análisis de conglomerados clasificó la base de datos de suministros en cinco (5) grupos a los cuales se le asignaron las etiquetas de identificación de acuerdo a las características del conglomerado al que pertenecía. De los conglomerados se obtuvieron los siguientes grupos:
• Bajo control: Suministros cuyos consumos se mantienen dentro de los rangos normales de acuerdo a la tarifa a la que pertenecen, además de presentar hasta dos (2) anomalías.
• Normales: Suministros cuyos consumos se mantienen dentro de los rangos normales de acuerdo a la tarifa a la que pertenecen, además de presentar de tres (3) anomalías a cinco (5) anomalías.
• A inspeccionar: Suministros cuyos consumos presentan variaciones negativas leves de acuerdo a la tarifa a la que pertenecen, además de presentar más de cinco (5) anomalías.
• Sospechosos: Suministros cuyos consumos presentan variaciones negativas medias de acuerdo a la tarifa a la que pertenecen, además de presentar más de cinco (5) anomalías y han sido inspeccionados.
• Altamente sospechosos: Suministros cuyos consumos presentan variaciones negativas graves o consumos iguales a cero (0) de acuerdo a la tarifa a la que pertenecen, además de presentar más de cinco (5) anomalías y no han sido inspeccionados.
De dichos conglomerados se seleccionó para inspeccionar los tres (3) últimos grupos, compuestos por 4.976 suministros, que representan el 12% de la población (43.053 suministros) los cuales presentan alta probabilidad de fraude.
De estos suministros fueron inspeccionados el 81% (4.032 clientes) detectando 1.340 suministros con fraude, obteniendo una efectividad de detección de fraude de 33%. Los que no fueron inspeccionados presentaban alta morosidad, inmuebles deshabitados, cerrados, servicio suspendido y/o ubicados en zonas de alto riesgo, según información del Sistema OPEN SGC.
El resultado de este análisis estadístico proporcionó las siguientes ventajas:
a) Reducción de la base de datos de suministros anómalos, lo cual facilita y optimiza el análisis.
b) Incremento en la detección de fraudes de 20 puntos porcentuales en relación al promedio de efectividad del año 2009 (13%).
c) Identificación de patrones de comportamiento (cinco conglomerados).
6- Conclusión y recomendaciones
Es primordial disponer de una base de datos con variables dinámicas, frecuentemente actualizadas para tener éxito en la aplicación de herramientas estadísticas en la detección de fraudes.
El estudio estadístico de la base de datos de clientes en empresas eléctricas obtiene patrones de comportamiento y agrupamientos de suministros que permiten mejoras en los procesos de detección de suministros con fraude eléctrico. Dichos estudios estadísticos están basados principalmente en técnicas de clasificación (Análisis Unidimensional, Multivariado y de Conglomerados).

El análisis de conglomerados constituye una aproximación alternativa para la ubicación de comportamientos que evidencien fraudes de consumo.
Se recomienda desarrollar e implementar un sistema para la detección de fraudes empleando herramientas estadísticas, para contribuir en la reducción del nivel de pérdidas de la empresa, mediante un incremento en la efectividad de detección de fraudes y una optimización de los recursos. Estas herramientas permitirán extraer de la base de datos de clientes tendencias y factores definitorios de fraudes considerando variables determinantes de patrones de consumo.
El sistema propuesto podrá analizar la base de datos de la empresa; sin embargo, será vulnerable a aquellos suministros que desde el inicio de su relación con la empresa tienen fraude eléctrico, clientes con demasiadas estimaciones, usuarios no ingresados al sistema, entre otros. Con el fin de focalizar y simplificar la detección de fraude, se recomienda que los próximos estudios estadísticos se realicen por zonas específicas, así mismo utilizar herramientas de inteligencia artificial asociada a máquina de vector de soporte (SVM).
7- Referencias
[1] Fernández, Rigoberto. Técnicas estadísticas multivariadas y sus aplicaciones a indicadores e índices económicos financieros de la actividad turística. Julio, 2006.
[2] Guglia, R. Mario. Métodos Multivariantes para la investigación comercial. Julio, 2006.
[3] Manual Latinoamericano y del Caribe para el control de Pérdidas Eléctricas. Organización Latinoamericana de Energía (OLADE).
[4] Peña, Daniel. Análisis de Datos Multivariantes. McGraw Hill.
[5] Santamaría Ruiz, Wilfredy. Técnicas de Minería de Datos para la Detección de Fraude.
Fuente
CIDEL Argentina 2010. CIDEL Argentina 2010 es un Congreso Internacional de Distribución Eléctrica que se llevó a cabo entre el 27 al 29 de setiembre de 2010 en el Hilton Hotel de la ciudad de Buenos Aires. Conjuntamente con el Congreso se realizó una Exposición de Equipos y Servicios relacionados con la Distribución Eléctrica, especialmente dedicado a Innovaciones Tecnológicas.
Organizado por la Asociación de Distribuidores de Energía Eléctrica de la República Argentina (ADEERA) y el Comité Argentino de la Comisión de Integración Energética Regional (CACIER), el congreso regional ha sido el ámbito de debate sobre las nuevas tecnologías y normativas del sector, así como también de las relaciones de las empresas con la sociedad en la que actúa.
El Congreso Cidel 2010 formó parte de las actividades regionales de CIRED
A lo largo de seis sesiones se trataron todos los temas vinculados a la distribución eléctrica en lo que hace a los avances tecnológicos en el diseño de la infraestructura, operación y mantenimiento, gestión, aspectos regulatorios. Una sesión individual abordó la sustentabilidad de la distribución eléctrica en su tres pilares: social, económico y medioambiental. Se destaca que esta fue la cuarta vez que se realizó este congreso en Argentina habiendo participado en otras oportunidades más de treinta países.
Los Autores
Jimmy Martínez – C.A Electricidad de Valencia, Venezuela
Jhonny Rivas – C.A Electricidad de Valencia, Venezuela
Luis Pereyra – C.A Electricidad de Valencia, Venezuela
Luis Molina – C.A Electricidad de Valencia, Venezuela
Mary Medina – C.A Electricidad de Valencia, Venezuela
Patricia Chirivella – C.A Electricidad de Valencia, Venezuela

Información relacionada
Más artículos sobre pérdidas no técnicas
Indicadores estratégicos para incrementar la efectividad de las inspecciones para las operadoras del servicio eléctrico Venezolano
Seguimiento y Control Preventivo de las Pérdidas no Técnicas de Energía en ELEVAL de Venezuela